https://gitee.com/ssssssss-team/spider-flow
平台以流程图的方式定义爬虫,一个高度灵活可配置的爬虫平台
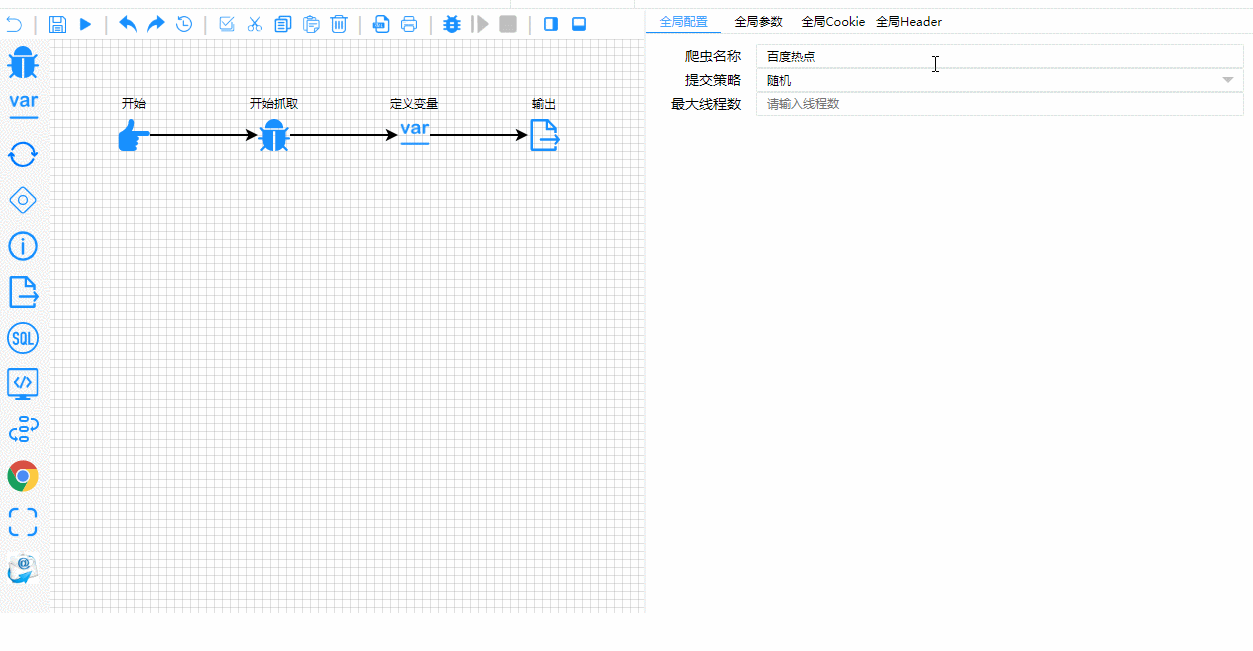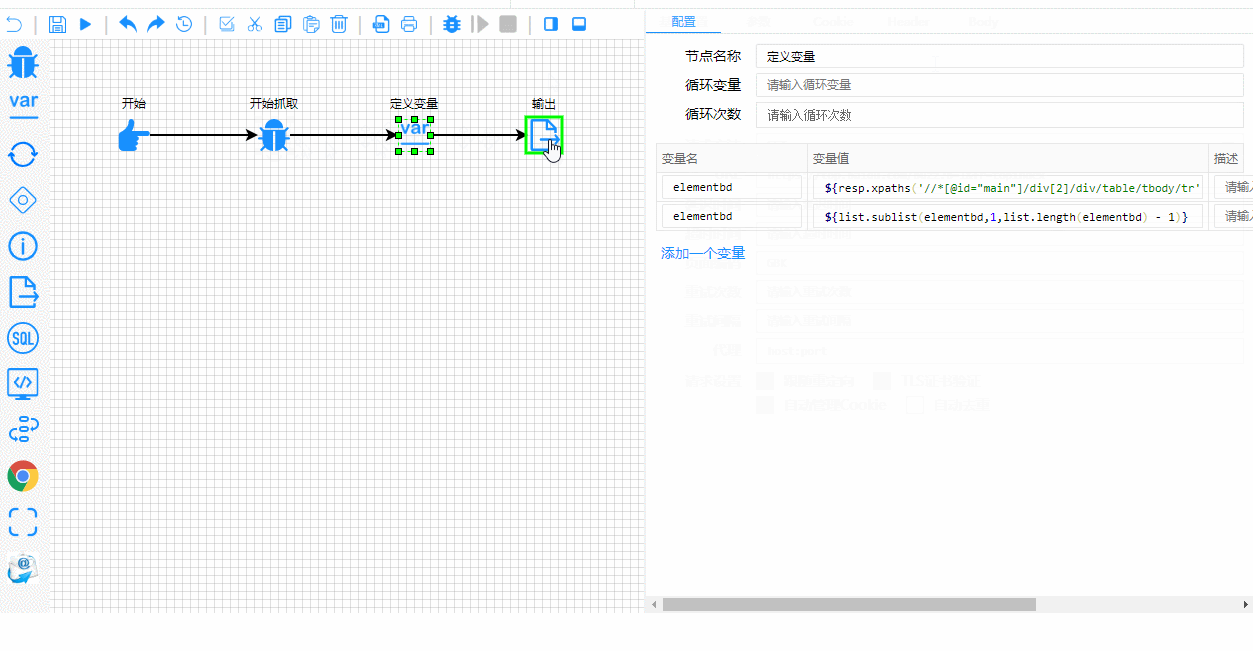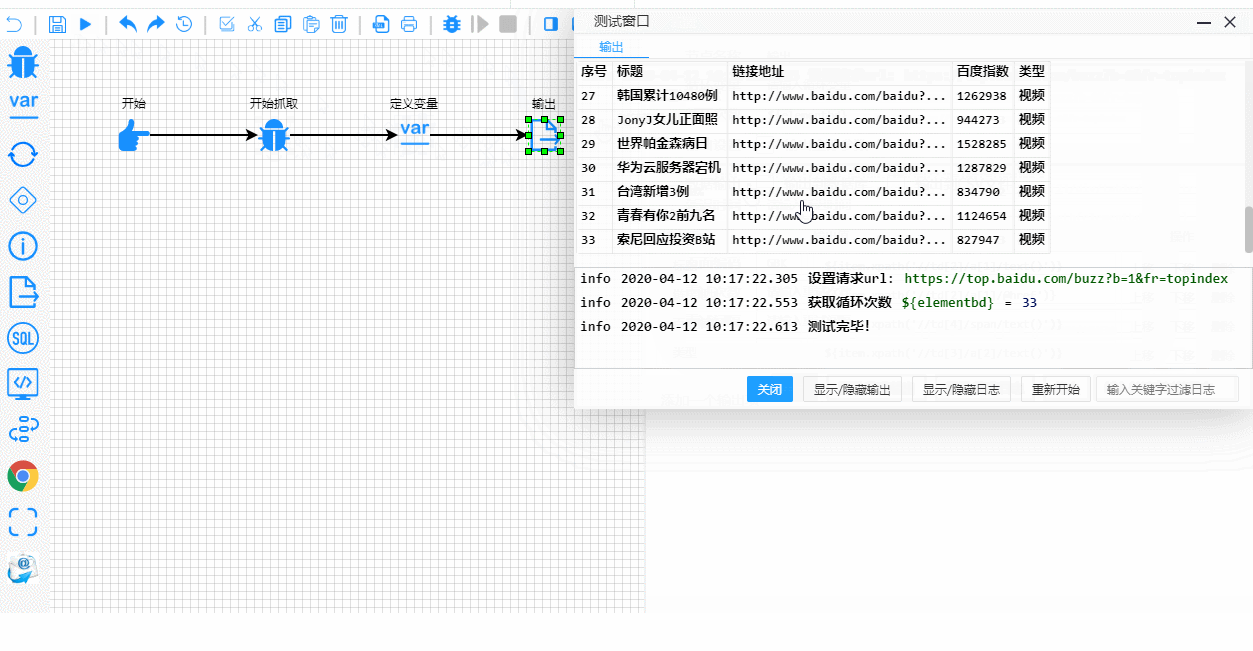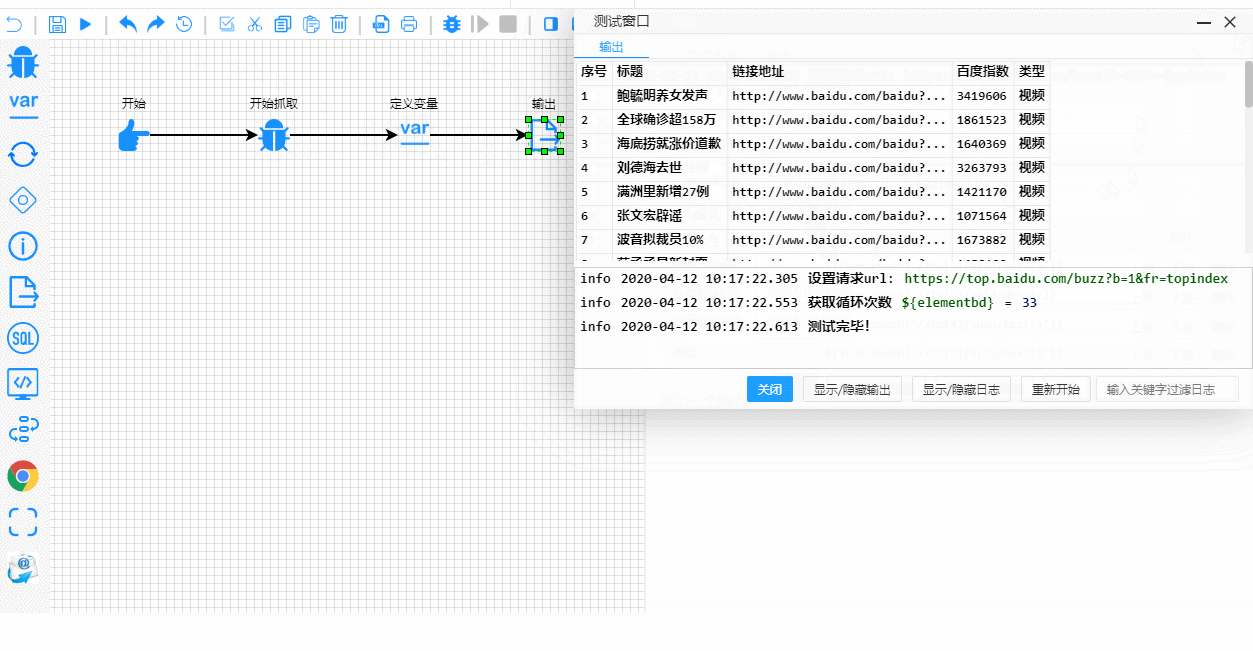
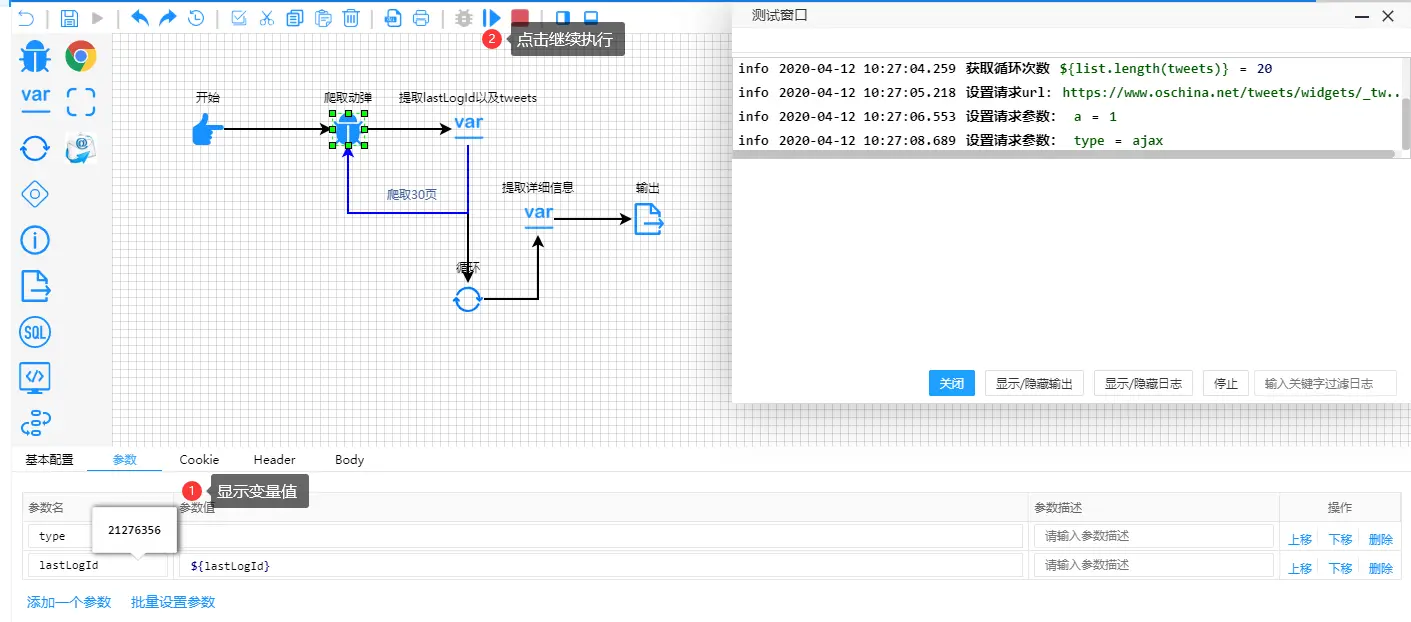
爬虫测试
Debug
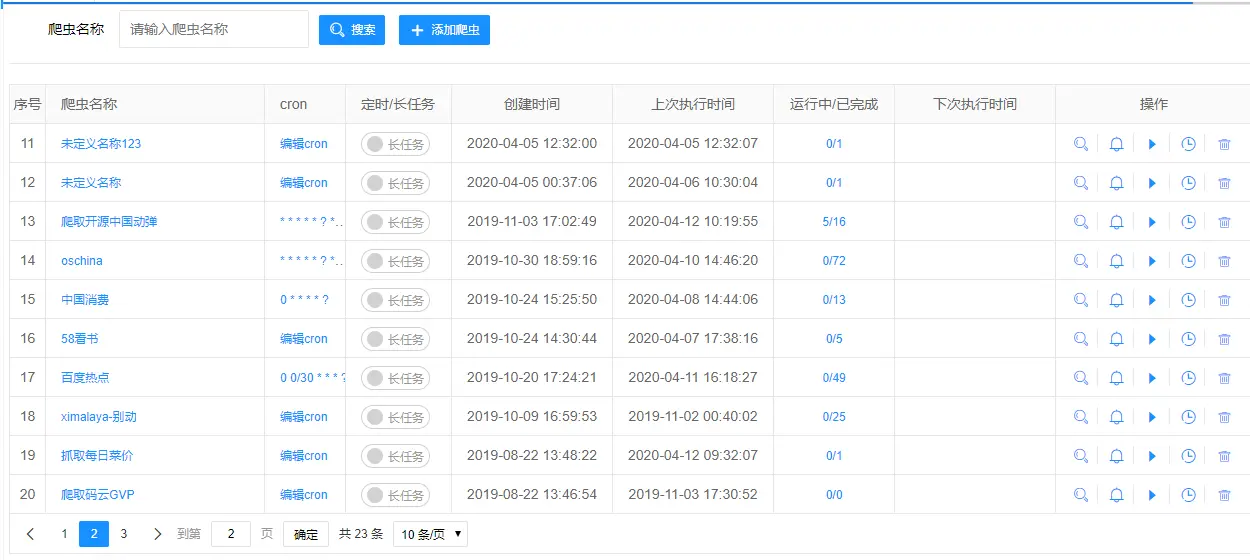
爬虫列表
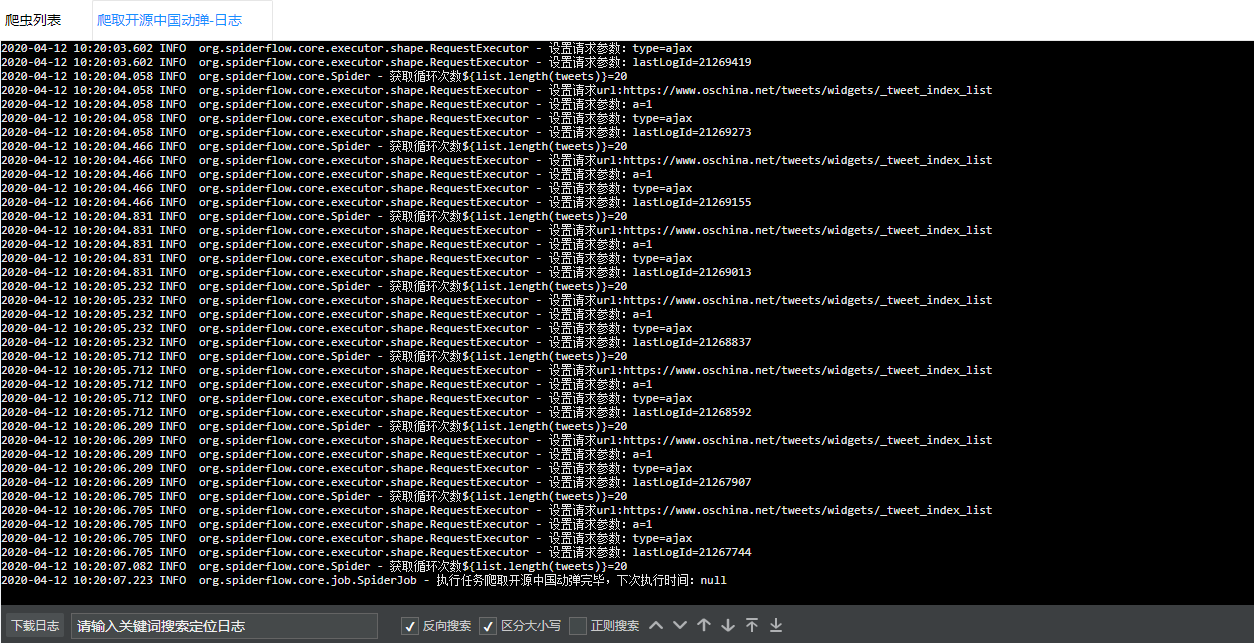
日志
好久以前看到过类似商业的爬虫工具
 全部评论: 0 条
全部评论: 0 条