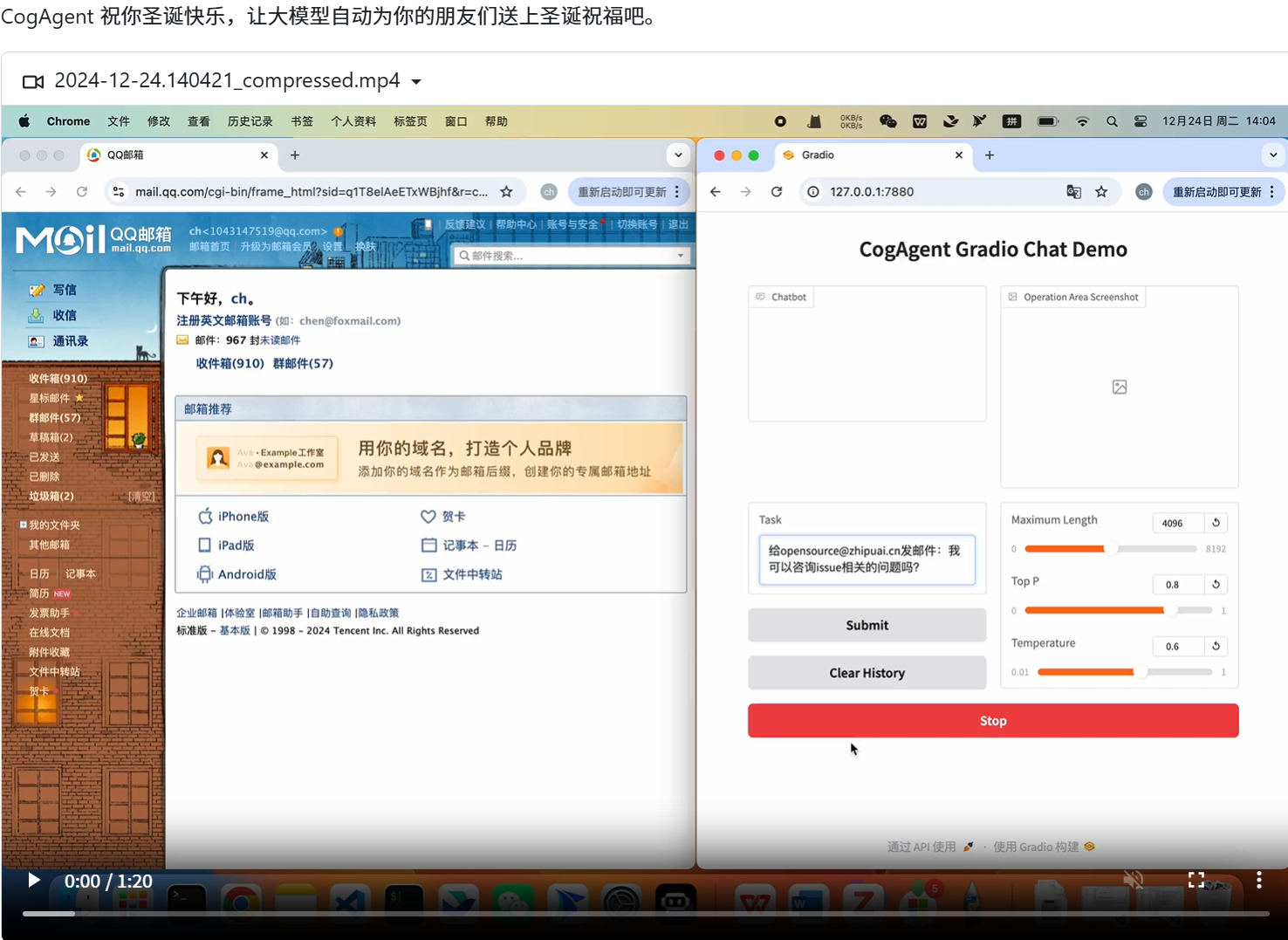
CogAgent GitHub 开源项目详细介绍
1. 项目概述
CogAgent 是由清华大学数据挖掘研究组(THUDM)与智谱AI联合开发的开源视觉语言模型(Visual Language Model, VLM),专门用于图形用户界面(GUI)的理解和导航。该项目旨在通过多模态大模型实现跨平台的GUI自动化操作,为开发者和研究人员提供一个强大的工具[2]。
2. 模型参数与能力
- 参数规模:CogAgent-18B 拥有110亿的视觉参数和70亿的语言参数,总计180亿参数。
- 图像分辨率支持:支持高达1120×1120分辨率的图像理解,确保了高精度的GUI组件识别和交互。
- 核心能力:
- 视觉问答:能够回答关于GUI界面的问题。
- 视觉定位:可以精确定位GUI中的特定元素。
- GUI Agent:能够执行按钮点击、文本输入和菜单导航等任务[5]。
3. 技术特点
- 双流注意力机制:能够同时处理视觉数据和文本信息,提升了对GUI组件及其功能的理解能力。
- 迁移学习:能够在不同类型的GUI之间进行泛化,减少了再训练的需求。
- 模块化设计:具备良好的可扩展性,方便开发者根据需求进行定制和扩展[18]。
4. 应用场景
- 自动化测试:可用于自动化测试工具中,提高测试效率和准确性。
- 智能助手:作为智能助手的一部分,帮助用户更高效地与软件交互。
- UI设计验证:在UI设计阶段,提前验证设计方案的可行性和用户体验[1]。
5. 开源与社区贡献
- GitHub仓库:项目已开源至GitHub仓库(CogAgent GitHub),并提供了网页版Demo供体验。
- 许可证:采用Apache 2.0许可证,允许商用[21]。
- 社区支持:鼓励开发者和研究人员参与项目,共同推动多模态大模型和Agent社区的发展[9]。
6. 最新进展
- CogAgent-9B-20241220:相较于之前的版本,新版本在GUI感知、推理预测准确性、动作空间完善性、任务普适性和泛化性等方面均实现了显著提升[13]。
7. 参考资料
通过以上介绍,可以看出CogAgent不仅是一个强大的视觉语言模型,还为GUI自动化操作提供了创新的解决方案。其开源特性也为广大开发者和研究人员提供了宝贵的研究和应用机会。
 全部评论: 0 条
全部评论: 0 条