背景
长亭的社区版 WAF 已经发布有一段时间了。从安全防护能力上讲,长亭差不多是国内 WAF 做的最好的厂商,主打的语义分析技术无论是检测准确性还是误报,都控制得很好。社区版据说也是企业版的检测引擎直接下放,虽然不一定是最新版本,但比其他开源 WAF 还是不知道高到哪里去了。
但社区版的检测性能是否会打折扣呢?以及在我自己站点特定的流量情况下,需要给 WAF 多少资源来保证 WAF 不会被打满了影响业务,这个问题还是需要实测一下的。本文也是尝试通过压测的方法来感受一下雷池社区版的实际性能表现,给大家一些数据供参考,同时也尝试发掘一下社区版雷池是否有可行的性能调优手段,在给定资源的环境下能压榨出更高的检测能力。
测试方案
测试环境
- CPU:Intel i7-12700
- 内存:64G DDR5 4800
- 内核:5.17.15-051715-generic
- Docker:20.10.21
- 雷池版本:1.3.0
测试部署
- WAF:添加一个站点,转发给同样跑在本机的业务服务器
- 业务服务器:一个 nginx,仅返回最简单的 200 页面
测试工具
wrk:一个简单的 HTTP 性能测试工具
wrk2:魔改的 wrk,可以以固定 QPS 发起测试
测试思路
本次测试主要关注跟流量检测相关的各个服务的性能基准,定义为当为单个服务仅分配且占满一个 CPU 核心时,可以支撑多少 QPS
测试使用两种请求:一是最简单的 GET 请求,没有请求体。二是 GET 请求带请求体,请求体是一个 1K 的 JSON
因为 WAF 性能的核心指标就是每秒可以检测多少个 HTTP 请求,所以 QPS 相对于网络层吞吐而言,是一个更加合理的参数。
测试过程
1. 判断服务的功能
先随意打个 1000 QPS,看看有哪些服务的负载会随 QPS 的变化而变化,用最简单的 GET 请求即可:
各个容器的负载情况:
由图可见,有三个服务的负载是跟流量相关的:
- safeline-tengine
- safeline-detector
- safeline-mario
从名字可推测,因为 tengine 是阿里 fork 并维护的 nginx 的魔改版,所以这个容器是一个反向代理,用来接收请求并代理给业务服务器;detector 应当是检测服务,nginx 会把请求发送给 detector 做检测,这一点从官方给出的 Nginx 快速集成免费 WAF 一文便可知;而 mario 应当是对检测日志做分析和持久化用的,从 detector 和 mario 的配置文件中可见一斑:
- detector 配置文件

- mario 配置文件

2. 简单请求测试三个服务的基准性能
先将所有服务的 CPU 使用上限改成 1 核,方法是在 compose.yml 文件里为服务增加 resource limit:

然后执行 docker compose up -d 让改动生效(需要在雷池的安装目录下执行,默认是 /data/safeline )
然后,我们使用 wrk 看一下能打到多高的 QPS:
QPS 打到了 4175
从上图可以看到,detector 的 CPU 达到 100%,首先成为瓶颈。
我们来看看 detector 的实际 CPU 占用情况: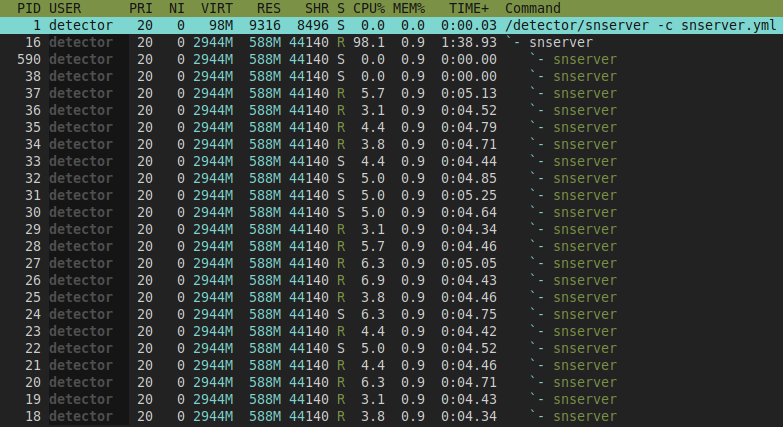
可以看到 detector 的进程名叫 snserver,是一个多线程的程序,线程数大约等于整机的 CPU 核心数(好像略多几个)。在限定了最高使用一核的情况下, 各个线程都有一点 CPU 占用,但都不高。
这样实际上会导致每个线程每次被唤醒只会跑一小会儿,一堆线程会来回切换,所以 context-switch 的开销会比较高。可以看到 detector 的配置文件里有这么一行配置,应该是在配置线程数,我们把它取消注释并改成 1 来减少 context-switch,试试看 QPS 能否再提升一些。这个文件在安装目录的 resources/detector/snserver.yml 位置,改一下然后重启 detector。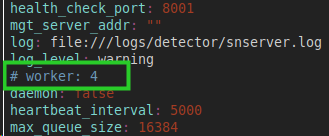
线程数减少,说明配置生效了。
nginx 也有这个问题,同样把 worker 数降下来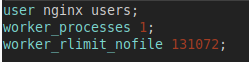
wrk 再测一下:
QPS 来到了 17000+,这个性能是比较真实的,还不错哦。
但是负载的变化上有个有趣的地方:
A. benchmark 启动之后,detector 与 mario 的负载同时达到 100%。同时这个过程中,可以观察到 mario 的内存在持续上升;
B. wrk 结束之后,tengine 与 detector 的负载立刻降回零,但 mario 仍然 100%,注意这个时候 mario 的内存占用超过 2 G
C. 又过了一会儿,mario 的 CPU 也降了下来,内存占用也降回 benchmark 前的水位(三百多 MB)
于是可以推测:
(1) 对于最简单的 GET 请求,detector 单核可以支撑 17000+ QPS
(2) 但在 17000 QPS 的情况,mario 一个核是不够用的,内存的持续上升推测是日志处理不过来导致队列在快速堆积,这一点从 wrk 停掉之后 mario 仍然在疯狂 100% CPU 也可以得到证明
(3)对于最简单的 GET 请求,mario 的性能是三个服务的瓶颈
由于 GET 请求过于简单,我们就不在这个场景下精确测定每个服务各自跑满单核能够支撑多少 QPS 了,我们直接用复杂请求来测,这样数据更有参考意义。
3. 复杂请求测试三个服务的基准性能
我们用 wrk 的 lua 脚本来生成复杂请求:
tcpdump 抓包可以看到发出去的请求是带有 1024 字节 body 的:
测得的 QPS 为 10000 出头:
各个服务的负载情况:
可以看到,detector 不出意外仍然是瓶颈,因为请求变得更大且复杂,检测引擎会消耗更多的 CPU 去检测属于情理之中。
同时,nginx 与 mario 的 CPU 占用均有一些下降。nginx 降低(65% --> 52%)是因为 QPS 的下降会拉低 nginx 的负载、同时请求大小的增加又一定程度上会增加 nginx 的负载,综合起来下降大于上升。而 mario 下降的更多(100% --> 47%),说明 mario 的开销跟 QPS 更敏感,对于请求大小反而不敏感。
从该用例,我们可以得到 detector 单核心的极限 QPS 为 10000
我们再来看下 tengine 的性能,为了让它可以最大限度承压,我们需要给 detector 和 mario 分配更多资源,我们都改成 4 核
nginx 单核心最高可以支撑 28000 QPS,还是很猛的
但 detector 的负载则升到了 326%,相对于之前单核极限的 10000 QPS,似乎多吃了一些 CPU,推测是某种多线程的同步会有额外的开销?
继续来测 mario 的单核心极限,因为这个东西超了负载会堆积数据,所以还不能靠单纯的 CPU 限制来测试。一个粗暴的方法是用二分查找来找到一个 QPS,然后利用 wrk2 的固定 QPS 方式来测试,标准为 mario CPU 占用接近 100% 但不出现内存的持续上升
这里的测试结果有些微妙。当我们限定 mario 的 CPU limit 为 1 时,即使只有 10000 QPS,它的内存也很难保证不持续增长。所以只能先放宽这个限制,先分配 2 核心给它。最终测得的一个相对可靠的数字为 11000 QPS 时可以基本保证 CPU 占用为 1 核且内存不会持续上涨。
但这个时候有一个更迷惑的点,就是上面测得 detector 单核最高可支撑 10000 QPS,但在 11000 QPS 时 CPU 开销居然到了 247%。这个数字着实有些奇怪。
测试总结
三个关键服务的性能表现如下表所示(请求含有 1K Body):
基于此表,我们可以估算一个综合单核 QPS 数,即雷池如果部署在一台只有一个 CPU 核的设备上,大约能承载多少 QPS,可以这样换算:
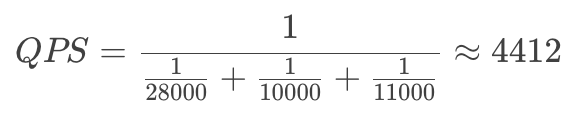
一些潜在的优化点:
- detector 多线程可能存在一定的锁竞争,导致多核开销偏高
- mario 内存占用在高负载时会持续升高,有 OOM 风险
可以看看长亭是否有后续的修复动作,尤其是解决掉上述优化点 2 ,这样后面还可以再测一下一台机器上不限制各服务的资源占用,整体打满之后能打到多高,否则目前测下来可能会炸内存,尤其单机内存相对较小的情况下。
 全部评论: 0 条
全部评论: 0 条