分享一篇今天看到的文档,非常值得认真阅读一遍:
https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
文档主要介绍了如何用langchain在私有数据集上做QA,也就是问答机器人。和如何对私有PDF文档进行内容总结
QA机器人代码:
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import CharacterTextSplitter
from langchain import OpenAI,VectorDBQA
from langchain.document_loaders import DirectoryLoader
from langchain.chains import RetrievalQA
# 加载文件夹中的所有txt类型的文件
loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt')
# 将数据转成 document 对象,每个文件会作为一个 document
documents = loader.load()
# 初始化加载器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
# 切割加载的 document
split_docs = text_splitter.split_documents(documents)
# 初始化 openai 的 embeddings 对象
embeddings = OpenAIEmbeddings()
# 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
docsearch = Chroma.from_documents(split_docs, embeddings)
# 创建问答对象
qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch,return_source_documents=True)
# 进行问答
result = qa({"query": "科大讯飞今年第一季度收入是多少?"})
print(result)
我们可以通过结果看到,他成功的从我们的给到的数据中获取了正确的答案。
PDF总结:
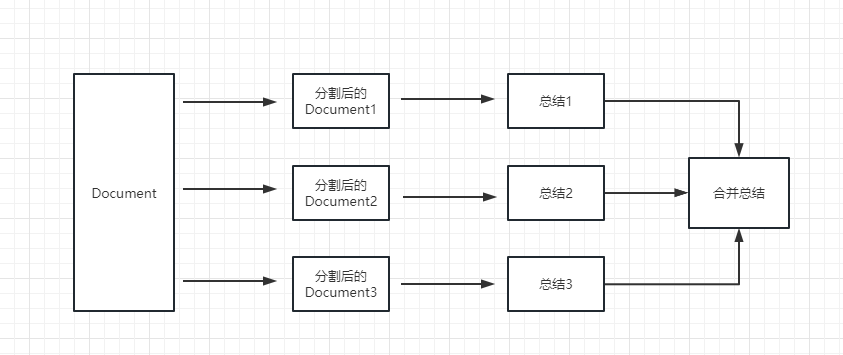
from langchain.document_loaders import UnstructuredFileLoader
from langchain.chains.summarize import load_summarize_chain
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain import OpenAI
# 导入文本
loader = UnstructuredFileLoader("/content/sample_data/data/lg_test.txt")
# 将文本转成 Document 对象
document = loader.load()
print(f'documents:{len(document)}')
# 初始化文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 500,
chunk_overlap = 0
)
# 切分文本
split_documents = text_splitter.split_documents(document)
print(f'documents:{len(split_documents)}')
# 加载 llm 模型
llm = OpenAI(model_name="text-davinci-003", max_tokens=1500)
# 创建总结链
chain = load_summarize_chain(llm, chain_type="refine", verbose=True)
# 执行总结链,(为了快速演示,只总结前5段)
chain.run(split_documents[:5])其他的内容虽然也有价值,但这2个更加实用一些把,暂且就分享这2个给大家~
 全部评论: 0 条
全部评论: 0 条